· Author: Lars Kruse · Essays · 18 min read
Say AI again — I Dare You!
AI is on the rise - the term is now used to describe any piece of software. In this rant I´ll take you through a journey, back to when AI was conceptually born to argue that we´re using the term wrong.

Cognitive Science - the foundation of AI
Cognitive science emerged as a research area in the mid-1950s and grew in the 1960s. It was a crossing of several diverse fields, especially psychology, linguistics, computer science, philosophy, and neuroscience began to converge with a shared goal: To understand the nature of intelligence, both human and artificial. The prevailing thought was that a deep understanding of human cognition would be crucial for any attempts to create truly intelligent machines.
Some of the more notable and recognized cognitive science celebrities and pioneers are Ulric Neisser, Noam Chomsky, Marvin Minsky. But my own heroes in this field are especially:
Michael Polanyi who stood father to the concept “tacit knowing” which argued that we know more than we can tell or explain, suggesting that a significant part of human intelligence is implicit and difficult to formalize in language.
Donald Schön articulated the concepts of reflection-in-action and situational back-talk and highlighted the importance of tacit knowledge and the dynamic interplay between action and reflection in professional practice, contrasting more purely rationalistic models of intelligence.
Hubert & Stuart Dreyfus a.k.a. “The Dreyfus Brothers”. The criticized and pointed out the limitations of formal rules and symbolic representations in capturing the skilled and intuitive nature of human expertise. They emphasized the role of embodied experience and tacit knowledge. An important contribution to the field was their skill acquisition model in which the highest level is referred to as mastery and where action is intuitive.
Lucy Suchman — her ethnographic studies of human-machine interaction emphasized the situated and contingent nature of action, challenging the idea that human behavior can be fully predicted or modeled by abstract plans. In the intro to her book “Plans and Situated Actions” she presents an example of the Trobriand Islanders of Papua New Guinea who navigate the waters between the islands in outrigger canoes in ways that aren’t based on pre-calculated routes, maps or compasses, but rather on constant attunement to the environment, emergent situated actions, tacit knowledge and skills. The Trobriand Islanders’ navigation serves as a metaphor for Suchman’s critique, which suggests that skilled human activity is often more about skillful improvisation and responsiveness to the immediate environment than about following a predetermined script.
Say ‘AI’ One more time!
Today the term “AI” is inflated to mostly refer to GPTs and LLMs. And arbitrary Dunning-Kruger 1 level services provided by gold diggers in the emerging AI era. I bet all the cognitive science pioneers would claim that what we refer to as AI today has little to do with what their field studies and conclusions defines as intelligence. At best our contemporary use of the word ‘AI’ is probably more like:
equilibristic manipulation of large data sets
While current generative AI excels at pattern recognition and generation, it fundamentally lacks the embodied experience, subjective awareness, and real-world interaction that underpin human cognitive abilities. I’m thinking especially of the concepts of tacit knowledge and reflection-in-action. I doubt that these abilities will ever come out of merely improving LLMs. Attempting to replicating the full complexity of human tacit knowledge and reflective abilities in AI is likely a very long-term and potentially fundamentally different endeavor, which probably can not be solved with generative language models. If it cloud, it would imply that human intelligence is nothing but - language.
How does that feel?
The philosopher Wolfram Eilenberger has made it a point to consequently name it “Machine Intelligence” instead of “Artificial Intelligence” to emphasize the distinction that the thing that LLM’s and GPTs represent is fundamentally different from the human intelligence.
But who cares if we use the term ‘AI’ wrong? Does it matter? Is cognitive science still relevant for today’s AI?
Microserfs
In highlighting the importance of embodiment and situatedness, I’d like to recap part of the Microserfs novel by Douglas Coupland — who probably is best known for his novel Generation X.
In Microserfs, the narrator, Dan Underwood, reflects on a kind of memory that seems to reside in the body, distinct from conscious, brain-based recall. As Dan and his fellow “microserfs” — young programmers at Microsoft in the early 90s — spend countless hours hunched over keyboards, often neglecting their physical well-being, they start to experience their bodies in a peculiar way. In Dan’s journal entries he touches upon this disconnect between their minds, intensely focused on code, and their increasingly atrophied and strangely aware bodies.
Dan notes how their bodies seem to accumulate a kind of memory of this lifestyle. The constant aches, the stiffness, the way their eyes strain — these physical sensations become a record of their time spent coding. It’s not a memory they can consciously access and narrate, but it’s a deeply felt, embodied history of their work. It’s tacit! Dan reflects on how different parts of the body seem to hold onto emotional residue or stress. It’s not about recalling a specific event, but more about the body carrying the weight of past experiences in a tangible way.
I believe most humans can relate to Dan’s reflections — and I assume that no GPTs can — So much for AI’s superior pattern recognition.
My point in this recap from Microserfs was that with all the prompt engineering and vibe coding going on, it’s now the GPTs that are becoming the microserfs. But they do not have the body to canalize the feeling of stress and burnout over being brutally exploited.
Is the world being overtaken by vibe coders hacking one-click deployable apps utilizing arbitrary LLM APIs an then shipping it as ‘AI-something-something’?
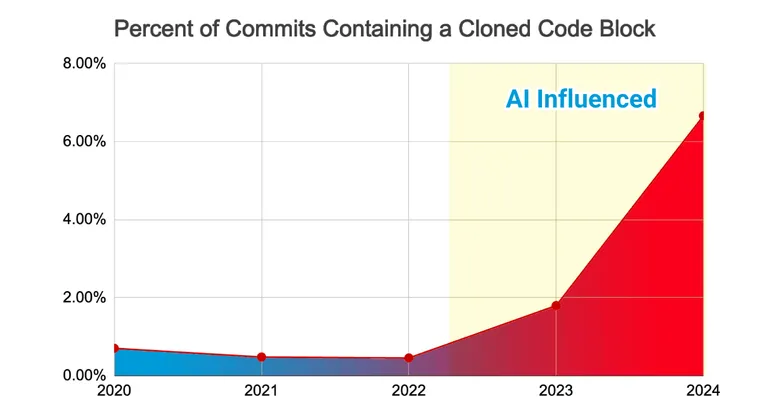
The recent research from GitClear
GitClear recently released some research that gave me the shivers — “OMG Is this really true!”
GitClear examined 211M lines of code in git commits and reveals that since the general availability of GPT assisted coding (≈2022) the amount of commits that contains a cloned code block (copy’n’paste reuse) is rising exponentially.
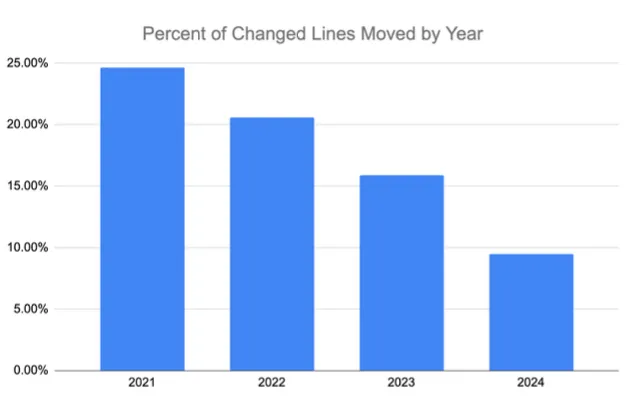
And at the same time the amount of moved code - which is the metric for refactored code has dropped from ≈ 25% of the commits in 2020-2021 to under 10% in 2025 with such a dramatic decline that the projection is that it’s going towards a round 0 in a year or two.
So if we’re projecting the current trends of the prompt engineering and vibe coding culture and enter a black mirror or ex machina doomsday perspective then we end up with a truly dark future.
The Rise of “Vibe Coding” and its Characteristics
Here are some of my personal dark projections of what will happen of we just go with the flow and don’t tak action.
Prompt Engineering as the Primary Skill: The core competency shifts from deep understanding of programming principles and software architecture to the ability to effectively prompt LLMs to generate code. It becomes more about guiding the AI’s “vibe” to produce something that looks like it works.
Superficial Understanding: Developers might increasingly lack a deep understanding of the code they’re using, treating LLMs as black boxes that magically produce solutions. This could lead to a decline in fundamental programming skills and the ability to debug or extend code effectively without AI assistance.
Copy-Paste Culture on Steroids: The trend of copy-pasting code, already highlighted by GitClear, could become even more rampant as developers rely on LLMs to generate snippets that they then stitch together without fully grasping their implications or potential interactions.
Technical Debt Accumulation: Without a focus on refactoring and code quality, projects could quickly accumulate significant technical debt, making them increasingly difficult and costly to maintain and evolve over time.
Homogenization of Code: If everyone relies on the same underlying LLM models and similar prompting techniques, there’s a risk of code becoming more homogeneous and potentially sharing similar vulnerabilities or inefficiencies.
Erosion of Craftsmanship: The focus might shift from the art and craft of software development to simply getting something working quickly, potentially leading to a decline in code elegance, efficiency, and robustness.
Developers as AI Orchestrators: The human developers become more like orchestrators of AI, their cognitive effort focused on prompting rather than deep problem-solving. They are somewhat detached from the underlying code. The no longer feel it in their bodies the same way the Microserfs in Couplands novel did.
AI as the Disembodied Microserf: The LLMs become the tireless, uncomplaining microserfs, generating code without any inherent understanding of the real-world implications or the “stress” of producing potentially flawed or unsustainable software. They lack (or hack) the human intuition and critical thinking that comes from experience and embodiment.
The Illusion of Productivity: There might be an initial surge in apparent productivity as code can be generated much faster. However, this could be a mirage if the underlying quality and maintainability suffer significantly in the long run.

Software is eating the world: This is truly a dark future - one that we should all be scared of — and perhaps we should not shout ‘AI’ in every single value proposition, as if it was an entirely good thing. When what we really get is a shit-load of copy’n’paste reuse of mediocre disembodied code. As individuals we must understand AI - not just brutally utilize it.
Clean it up!
If software is eating the world, then our job as software developers should probably rather transform into “software tamers” as opposed to merely “AI prompt orchestrators”. We should revisit some hard learned Clean code and SOLID virtues. I’ll list just a few of the ones that I’d claim that GPT generated code is consistently bad at:
- DRY - Don’t repeat yourself
- Keep it short - less code is better
- Refactor - continuously improve
- Open/Closed …for expansion and modification respectively 2
- Use abstractions that do not depend on details.
Most of the clean code principles, as defined by Uncle Bob, the father of the Clean code paradigm, assumes that the code is object oriented (OO). But I’ve left all the OO related principles out from the list above, because I’ve noticed in my latest development team with high representation of gens Y+Z; They don’t fancy OO the same way gen X and boomers do.
Is it just a matter of taste? Or is it contemporary coding just a different paradigm? I don’t know. But I’ll admit that I’m old, and I don’t want to start a fight about whether OO code is better or not (it is 🤷). But I’d say that OO principles in general is something that most GPT’s are notoriously bad at - or more precisely; it’s not the first choice of approach; copy’n’paste reuse of snippets is. AI tends to produce code that is more about getting something working quickly. It often lacks the modularity, encapsulation, and abstraction that are hallmarks of good OO design and Clean Code. So unless you prompt the GPT specifically in the direction of OO code or other principles of component reuse — you won’t get it.
Imagine the horrifying mess you can create, if you let the GPTs loose on your (up until now) object oriented code base — and it starts flooding it with copy’n’paste reuse snippets.
But everyone is soooo much more productive with AI assisted code — so what’s the problem - really?
DevOps and Continuous Delivery to the rescue
True, one of the benefits we presumably get from GPT assisted code is — a lot of code. Hence everybody feels “…sooo much more productive”. But is that a good thing? Is that the right metric?
The GitClear research ought to have the same effect on us, as when we got the first scientific proof from ice core drillings that climate change is caused by humans and we seriously need to do something very different! Only with this proof in hand did climate concerns move it up the chain from NGOs to governments and legislation.
Hopefully, nothing is so bad that it’s not good for something. I have my hopes up for insights like the GitClear research to be able to reignite the whole DevOps and Continuous Delivery agenda, and that we — the DevOps community — is being called upon us to save the world — again (we were also called in to make agile look like a success rather than a hoax - remember?)
DevOps has always claimed — even before GPTs and LLMs were a thing — that programming as an isolated it-works-on-my-computer discipline is really not that hard. However;
Consistently releasing software into the hands of the end users, as a continuous flow, without breaking anything on the way
…that’s really difficult.
And the DevOps challenge to all World’s developers then became: “You build it — you run it!” I still see a lot of developers who still doesn’t dare to pick up that challenge. They will rather continue their semi-religious fourth-night-cycle and simply throw their code over the fence to be picked up by someone who puts it into production — magically.
I wonder how well the vibe-coding paradigm fits with the somewhat less buzz-word inflated “hypercare” concept; a term used in DevOps to describe the period where it’s the software development team who does all the maintenance and operations on the product. The sooner the product is stable, the sooner it can come out of hypercare.
I wish the autodidact prompt engineers and vibe coders good luck with the hypercare.
DORA perspective
I want to mention DORA (ours — not theirs). I’m talking about The DevOps Research and Assessment institute (ours) - not the EU Digital Operational Resilience Act (theirs).
DevOps and specifically the DORA metrics gives us really good tools to measure on delivery throughput and delivery stability. It turns out that these Software Development Life-cycle concepts have a significant influence on code quality.

Each year the State of DevOps report gives an insight into how the four cohorts; Elite performers, high performers, medium performers and low performers of roughly equal size are performing in the industry. In 2024 the analysis was based on 39K+ respondents so the numbers are solid.
In 2024 an interesting phenomena played out in the numbers. The high performers had much higher change failure rate (introducing more failures) than the medium performers, but despite the troublesome stability indicator they beat them through superior performance in the throughput indicators.
The point being that if you have low change lead times (work travels fast from idea inception to end user delivery) and you deploy frequently (Continuous Delivery) and you are quick on your feet to recover if failures slip through to production. Then you can — apparently — get away with a relatively high change failure rate.
On the other hand if you seek perfection in you change failure rate at the expense of throughput, then it in general there’s a lot of shots that you don’t take — and we all know that you miss 100% of the shots you don’t take.
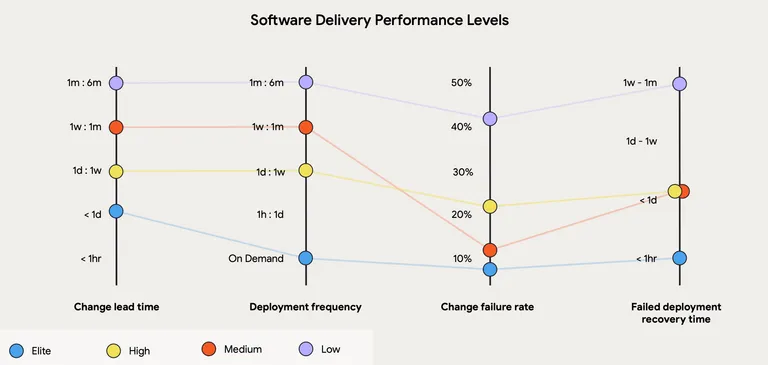
HEY! That’s good news for all the vibe coders isn’t it? If “throughput beats stability” and we’re “…sooo much more productive” when using AI then crabby copy’n’paste code can live — if you can up the throughput!
Well - maybe it’s not that simple: DORA is completely on par with the GitClear research and although the 2024 “State of DevOps” report is apparently mostly positive in it’s conclusions on AI use, they do project their findings from the 2024 report like this:
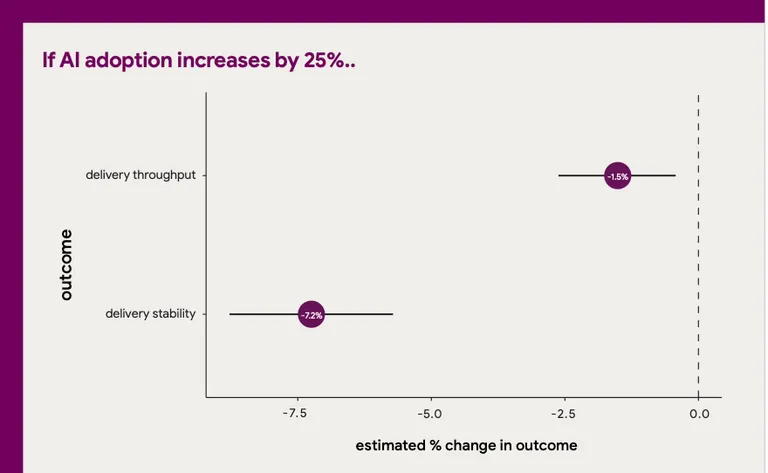
Stability is way down with 7.2% but even throughput is down with 1.5%. …as a direct consequence of everyone being “soooo much more productive with AI”
I’ve seen enough software teams to recognize — I can even feel it in my body — that especially the change lead times will suffer hard from a poorly organized codebase; Onboarding of new colleagues takes ages, there’s no tests to run, no documentation to read, It’s not even clear how I get my development environment up and running, there are no coding standards and with all the copy’n’paste reuse, my strongest weapon is no longer my debugger, but the search’n’replace function. …or I could shovel it to an AI prompts and have it do it’s magic.
The Change lead times is the hardest throughput factor to get right. The two deployment related metrics; frequency and recovery can be overcome by automation and Infrastructure as Code - you can even get help from and AI to do that. So they are probably less of a challenge.
But how can we possibly improve the change lead times — in general, including the ones for rework and maintenance (“you build it you run it” remember!) — by adding crabby, mediocre unSOLID and unClean code?
The intelligent thing to do now — I can feel it in my body — would be to stop auto generating more code, and to start refactoring, reuse and abstract. To build quality in. To shift-left. The intelligence that the Microserfs that are writing our code today have access to is artificial. Disconnected from gut-feelings.
The hyper flexible rubber pentagon
This is my outro - I’m offering a solution; “The hyper flexible rubber pentagon” 3. I’ll introduce a perspective that was inspired by Kent Beck’s eXtreme Programming. In the 1st edition of the book he came up with a bold idea to break the curse of the infamous Iron Triangle. I took it a bit further and potentially found an acceptable — or at least conscious — approach to dealing with all the clutter from vibe coding. Or just poor quality in general.
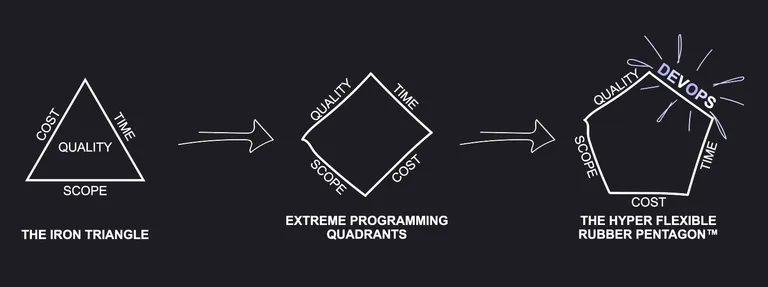
The infamous Iron triangle from traditional un-collaborative hostile requirements management; everything is in a complete lock down. The customers is screaming: “I want all my features, on time, on budget and with indisputable impeccable quality”. The only thing the team can do is to throw in more people and wait for Brook’s law to kick in. This project is doomed — it will die under the weight of Brook’s law:
Adding manpower to a late software project makes it later
Next step is Kent Beck’s contribution, from the first editions of his eXtreme Programming book. In which he courageously invites the customer to freely pick, own and control any three and as long as the development team can fully own and control the fourth — it will be a happy ending, guaranteed!
How it works: Imagine the client locks in on scope, cost and time, and the only thing the team can control is quality, then hacking a solution in a no-code tool or vibe coding the whole thing will probably get you there. But most clients are relatively picky about whether the investment actually delivers any quality (≈value) so more likely the client locks in on quality, time, and cost and the team is left to control the scope. Well that’s a minimum Viable Product - isn’t it!
I can see Beck’s bold statement play out; as long as the team is left to fully control one of the edges, it’s not a complete lock down. The curse from the iron triangle is broken.
But aren’t we still just fooling around in an agile bubble, where everyone is writing code that works-on-my-computer? How do we get this into the hands of the end-users? What about automated deployment, infrastructure as code, automated end-to-end tests, configuration management, keeping the size of the code base in check, documentation — and all that jazz. Or we can just plainly ask the client,
Imagine that we simply ask — With reference to the DORA metrics — “which performance cohort, do you want to be in?”.
If the client consciously chooses — or can live with — being in the low or medium performer cohort and also accepts low quality, then it’s probably still OK to vibe code and prompt engineer the solution. I can easily see this work well. If DevOps and Quality is consciously sacrificed.
In “The mythical man-month” Fred Brook argued that the first solution is a throw-away, used to get a feel for the situation, and then the second one is done right. Alberto Savoia, who came up with the concept of a pretotype (not a spelling mistake) in which he paraphrased Eric Ries’ “Fail early” (that’s the Minimum Viable Product concept from “The Lean Startup”) to rather “Fail cheap”.
I’m very much in favour of the approach argued by Brook, Ries and Savoya that we should get it right, before we build it right - After all; our idea may not actually have a market-fit — or make the intended end-users happy. And if that’s the case we want to know as soon and cheap as possible.
I believe this is an area where vibe coding and prompt engineering can really shine and already have made low-code and no-code solutions obsolete before they ever became mainstream. In this specific scenario where we’re exploring if we’re trying to build the right it, rather than building it right, it is probably all about being “…sooo much more productive” and getting something, anything into the hands of the end-users to capture their immediate response and feedback; “are we building the right thing”.
Maybe in this scenario we can save all future hypercare, DORA metics, IaC, code quality concerns for later. It’s a throw-away.
But as Brooks also highlighted in “The mythical man-month” — in 1968:
The real problem starts if the management then choses, not to throw away the throw-away.
This project is doomed!
Footnotes
The Dunning-Kruger effect is a cognitive bias in which people with low ability at a task overestimate their ability and competence. Dunning and Kruger are actually also accredited to belong to the cognitive science field. In the context of AI, we see this effect manifesting in the overconfidence of users and developers alike, and the sheer amount of AI experts who offer their services is alarming; They can simply not all be experts. ↩
In context of Semantic Versioning (SemVer); favor minor bumps over major bumps ↩
Credits for the visuals and the pentagon name to my friend and former colleague Anias Held. ↩